Many teams don’t struggle with AI capability but with where and how to use it.
The models work, APIs are accessible, tooling has matured enough that integrating an LLM into a workflow takes hours, not months. And yet, McKinsey’s 2025 State of AI found that only 23% of enterprises are scaling AI systems into production. Another 39% remain stuck in experimentation. The gap between “we built a demo” and “this runs reliably every day” keeps growing.
The most common reason? Overengineering.
Overengineering happens when AI gets added without clear system intent.
A classification task becomes a multi-agent pipeline.
A simple retrieval workflow becomes an agentic architecture with six LLM calls per query.
The system gets more complex, harder to debug and no better at the thing it was supposed to do.
Good AI system design is intentional, constrained and well-structured. Whether you’re preparing for a system design interview or building production infrastructure, the principles are the same.
Our article is how to get there.
Start with System Design, Not AI
Before introducing any artificial intelligence component, define what the system is supposed to do at a high-level. It gets skipped constantly.
Define system goals, inputs and outputs
- What goes in?
- What comes out?
- What does the system need to achieve?
These questions have clear answers for most workflows, and those answers should be written down before anyone even mentions a model. If you can’t describe the system’s purpose in one sentence, then the architecture will reflect that confusion.
Identify decision points in the workflow
Walk through the workflow step by step.
- Where does a decision happen?
- Where does uncertainty exist?
- Where does a human currently make a judgment call?
These are your candidate locations for AI. Everything else should stay deterministic.
Separate deterministic logic from uncertain tasks
If a decision is predictable and rule-based, AI is likely unnecessary. A status check, a threshold comparison, a routing decision based on known criteria – all these belong in traditional logic.
AI belongs where the input is ambiguous, the patterns are complex or the volume makes human review impractical.
Where AI Adds Value in a System
AI is most useful where uncertainty exists. Designing systems around this principle prevents the most common overengineering mistakes.
Pattern recognition and classification
Categorizing documents, detecting anomalies in transactions, routing support tickets by intent – tasks where AI models excel because the inputs are variable and the patterns are learnable. A well-trained classifier running on a simple pipeline delivers more real-world value than most elaborate architectures.
Generative tasks
Text generation, summarisation, extraction, content drafting – the generative use cases where LLMs shine. These work well when the output has a clear validation path.
Retrieval-based systems (RAG workflows)
When the system needs to answer questions grounded in specific data like internal documentation, product catalogues, knowledge bases, retrieval-augmented generation is the pattern.
A query hits a vector database, retrieves relevant context and an LLM generates an answer grounded in that context. RAG stays simple when you keep the retrieval pipeline clean and the prompt structured.
AI-powered interfaces vs. backend logic
Sometimes AI belongs at the interface layer: a natural language query parser, a conversational UI, a search experience. Sometimes it belongs in the backend: classification, scoring, extraction.
Where the AI component sits in your architecture affects latency, cost, scalability and debuggability.
Where AI Does Not Belong
Misplacing AI is the fastest path to overengineering.
Deterministic workflows
If the logic can be expressed as a decision tree, a set of rules or a lookup table, an LLM adds cost and unpredictability without adding value that you need in the first place. Don’t use AI to do what a conditional statement does perfectly well.
Critical system paths without fallback
AI outputs are probabilistic. Putting an LLM on a critical path with no fallback is asking for production incidents. Every AI component in a system needs a graceful degradation path.
High-risk decisions without validation
Financial approvals, medical recommendations, legal determinations require human oversight. AI can assist and surface information, but the final decision should pass through a validation layer.
Common misuse patterns to avoid:
- Using generative AI where a database query would suffice;
- Running multi-agent orchestration for a single-step task;
- Treating LLM output as deterministic;
- Adding AI just because stakeholders asked for “something with AI”.
Designing Simple AI System Architecture
Keep architecture understandable before making it advanced.
Basic AI pipeline:
Input → preprocessing → model call → output validation → action.
This pipeline handles most AI use cases. Start here and add complexity only when this pattern demonstrably can’t solve the problem.
When to introduce retrieval (RAG)
Add retrieval when the AI component needs context that isn’t in the model’s training data:
- company-specific documents;
- recent data;
- domain knowledge.
The architecture extends to:
input → query embedding → vector search → context assembly → model call → output.
Datadog’s 2026 State of AI Engineering report found that agentic framework adoption nearly doubled year over year, rising from 9% to 18% of organisations, but the majority of production AI systems still run on simpler patterns.
Using cache to reduce cost and latency
If the same queries hit your AI pipeline repeatedly, cache the responses. Semantic caching (matching similar queries to cached results) reduces API costs and improves responsiveness without adding architectural complexity. One of the highest-ROI optimisations in AI system design and one of the most overlooked.
Avoiding premature multi-agent systems
Multi-agent architectures are powerful for complex, multi-step reasoning tasks. They’re also expensive, hard to debug and overkill for 90% of current production use cases.
Deloitte’s 2026 State of AI report found that only one in five companies has a mature governance model for agentic AI — even as adoption accelerates. Start with single-purpose AI components. Graduate to agents when the use case genuinely demands autonomous multi-step reasoning.
| Feature | Simple Pipeline | Agentic Architecture |
|---|---|---|
| Best for | Classification, extraction, single-step generation | Multi-step reasoning, dynamic tool use |
| Complexity | Low | High |
| Debuggability | Straightforward | Requires dedicated observability |
| Cost | Predictable | Variable (scales with steps) |
| When to use | Most production use cases today | Complex workflows with genuine autonomy needs |
Prompt Design as a System Interface
Prompts shape system behaviour. In production AI systems, they deserve the same discipline as any other system interface.
Structuring prompts for consistency
Use clear instructions, define the expected output format and include examples where they reduce variability. A well-structured prompt acts like a contract: specify the role, the task, the constraints and the expected response schema. Teams that treat prompts as throwaway strings end up debugging output randomness instead of building features.
Handling variability in outputs
LLM outputs are inherently variable. Even with identical prompts, responses can differ in structure, length and content. Handle this with validation layers downstream: parse outputs against expected schemas, reject malformed responses and retry or fall back when the output doesn’t match.
Prompt versioning and iteration
Treat prompt versioning like code versioning: track changes, test regressions before deploying and roll back when quality degrades. Tag each version, log which version produced which outputs and tie changes to measurable quality metrics.
Add Guardrails, Not Complexity
AI systems need constraints rather than more intelligence.
- Output validation and filtering.
Every AI output should pass through a validation layer before reaching the user or the next system. Schema validation, content filtering, format checking are cheap to implement and prevent the most embarrassing failures.
- Confidence thresholds.
When the model’s confidence is low, route to a fallback: a human reviewer, a simpler algorithm, a “I don’t know” response. Confident wrong answers are worse than honest uncertainty.
- Fallback mechanisms.
Every AI-powered path needs a non-AI alternative. When the API is down, when the model hallucinates, when latency spikes, then the system should degrade gracefully rather than fail. Completely.
Minimum guardrails for production systems:
- Input sanitisation (prevent prompt injection);
- Output schema validation;
- Confidence-based routing;
- Rate limiting and cost controls;
- Logging for every model call (input, output, latency, token count).
Design for the problem, not the model
Start with the system constraints that matter most, then use AI where it removes complexity or improves outcomes. Simpler architectures are usually easier to scale, maintain, and trust.
Designing Workflows Around AI
AI should fit into workflows, not replace them entirely.
Human-in-the-loop decision points
For high-stakes or ambiguous decisions, design explicit review steps where a human validates the AI’s recommendation before the system proceeds. Content moderation, financial scoring, medical triage, anywhere the cost of a wrong decision outweighs the cost of a short delay.
Automation vs. augmentation
Classification of low-risk support tickets? Automate.
Drafting a legal summary for client review? Augment.
The distinction determines how much control and oversight the workflow needs. Default to augmentation when the stakes are high or the domain is complex.
Workflow orchestration basics
When AI is one step in a larger process, keep orchestration simple: a task queue, clear handoffs between steps and well-defined input-output contracts for each stage. Avoid building custom orchestration engines when existing frameworks handle the pattern.
Managing Tradeoffs in AI System Design
Every AI system involves tradeoffs. Making them explicit prevents surprises in production.
| Lower End | Higher End | How to Evaluate | |
|---|---|---|---|
| Accuracy vs. latency | Faster responses, more errors | Slower, more precise | Match to user expectations and use case criticality |
| Cost vs. scalability | Cheaper per call, limited scale | Higher cost, elastic scaling | Model against realistic traffic projections |
| Flexibility vs. reliability | Adaptable, less predictable | Constrained, more stable | Prioritise reliability for production; flexibility for experimentation |
Scaling AI Systems Without Overengineering
Start small, then expand deliberately.
- Single-purpose AI components first.
One model, one task, one clear input-output contract. Compose these into larger systems when the individual components are stable and well-understood.
- Observability and logging.
Log every AI interaction: inputs, outputs, latency, cost, error rates. Without observability you can’t optimize, debug or explain what the system did or why.
- Iterative improvement loops.
Collect feedback on AI outputs. Use it to refine prompts, adjust confidence thresholds and improve over time. The best AI systems improve continuously because they’re designed to learn from production behaviour.
A Practical High-Level Architecture You Can Use
Most AI-enabled systems fit a five-layer reference model. Before reaching for a framework, map your system to these layers.
Input layer
Where data enters: user queries, uploaded documents, API calls, webhook events. This layer handles parsing, normalisation and initial validation. Malformed or adversarial inputs get caught here, before they reach anything expensive.
Processing layer
Deterministic logic lives here: routing, enrichment, transformation, business rules. If a request can be resolved without AI — a database lookup, a rules-based decision, a cached response — it gets handled at this layer and never touches the model.
AI component
The model calls itself. Keep it thin: one model, one task, one clear prompt. Pass in only the context the model needs. If you’re using RAG, the retrieval step feeds context into this layer.
Validation layer
Every AI output passes through validation before moving downstream. Schema checks, confidence thresholds, content filtering. This layer turns probabilistic outputs into something the rest of the system can trust. If validation fails, route to a fallback — not to a crash.
Decision and action layer
The validated output triggers an action: a response to the user, a database write, a notification, a handoff to a human reviewer. This layer owns final decision logic and human-in-the-loop checkpoints for high-stakes workflows.
The flow: Input → processing → AI component → validation → decision/Action. Each layer has a single responsibility, a clear interface and a fallback path.
Common Mistakes That Lead to Overengineering
Most complexity comes from avoidable design decisions:
- Starting with tools (LangChain, vector databases, GPU clusters) instead of problems;
- Overusing agentic or multi-agent setups for tasks that don’t require autonomy;
- Skipping validation layers because “the model is good enough”;
- Treating AI output as deterministic when it is fundamentally probabilistic;
- Fine-tuning when prompt engineering would suffice;
- Writing custom coding for AI orchestration when existing frameworks handle the pattern.
Design for Reliability, Not Novelty
AI systems don’t need to be complex to be powerful. They need to be well-placed, well-bounded and easy to reason about.
The teams shipping real-world AI systems at scale tend to share a pattern: simple architectures, strong guardrails, clear ownership of each AI component and a willingness to use traditional logic where it works better. The novelty is in what the system achieves, not in how many layers the architecture has.
At Lerpal, we help organisations design and build AI systems that work in production: scalable, observable, maintainable. We’ve spent years integrating AI into real systems across media, fintech and enterprise software, and the approach is always the same: start with the problem, design the architecture, add AI where it genuinely helps and keep everything as simple as the requirements allow.
Let’s design an AI system that works without the unnecessary complexity.
“How much does it cost to build a fintech app?”. It’s the first question every founder asks and nobody enjoys the answer: it depends. Depending on who you ask, developing a fintech app costs somewhere between $50,000 and $500,000+.
That range is about as useful as answering “how long is a road”. It tells you nothing about your road.
The global fintech market reached approximately $395 billion in 2025 and is projected to hit $461 billion in 2026, growing at an 18% CAGR. Global fintech investment recovered to $116 billion in 2025, up from a seven-year low the year before.
The money is flowing.
The question is how much of it you’ll need and how to spend it without watching the budget moonwalk right past your original estimate.
This guide breaks down fintech app development costs based on what drives spending without generic feature lists.
Whether you’re planning to develop a fintech app from scratch or evaluating fintech application development partners, understanding the real cost drivers gives you a foundation for conversations that start with numbers rather than guesses.
What Determines Fintech App Development Cost
Before opening a spreadsheet, understand the five forces that shape every fintech app development cost:
1/ App complexity.
A basic payment app with a few screens and one integration has a fundamentally different cost profile than a wealth management platform with real-time portfolio tracking, AI-driven recommendations and multi-currency support.
Complexity compounds: every additional feature adds development time, testing time and integration time. The difference between a basic app and an advanced app can easily be a 3-5x cost multiplier.
2/ Compliance requirements.
Financial services live under regulatory scrutiny. KYC/AML, PCI DSS, GDPR, SOC 2 – each requirement adds development work, security architecture and ongoing maintenance.
A fintech app that handles payments in Europe has different compliance needs than one operating in the US, and if you’re targeting both the requirements stack. Compliance work can account for 15-25% of total development costs on a complex fintech product.
RegTech deal volumes rose to 519 in 2025, reflecting how seriously the fintech industry is treating regulatory infrastructure as a product-level concern.
3/ Integrations.
Payment gateways, banking APIs, credit scoring services, identity verification providers – every third-party integration adds development time and ongoing dependency management.
The fintech app depends on these integrations working reliably, which means building error handling, fallback logic and monitoring around each one.
4/ Security expectations.
Financial service users expect bank-grade security. End-to-end encryption, secure authentication, fraud detection, transaction monitoring.
These aren’t optional features and they cost money to implement all properly.
Cutting corners on security in fintech is the kind of decision that saves money for about six months and then costs everything.
5/ Platform choice.
Web, iOS, Android or all three? Each platform adds development and testing effort. Cross-platform development frameworks (React Native, Flutter) can reduce cost, but they come with tradeoffs in performance and native functionality.
The platform decision shapes the overall cost of mobile app development significantly.
Fintech App Cost Breakdown
Here’s a realistic fintech app development cost breakdown for a mid-complexity fintech application in 2026:
Design (UX/UI): 10-15% of total budget.
User experience in fintech is a trust signal. Poorly designed financial apps don’t get second chances. Users who don’t trust the interface won’t trust it with their money. Budget for proper research, wireframing, prototyping and user testing.
Development (frontend + backend): 40-50% of total budget.
The biggest cost driver. Frontend development builds what users see and interact with. Backend development handles the business logic, data processing, API orchestration and infrastructure. For fintech, the backend is typically more complex because financial operations require transaction accuracy, concurrency handling and audit trails.
Integrations (APIs, payment systems): 10-15% of total budget.
Connecting to payment processors, banking APIs, identity verification services and data providers. Each integration requires development, testing and ongoing monitoring. Some fintech API providers charge transaction fees on top of development costs.
Security & compliance: 10-20% of total budget.
Encryption implementation, secure authentication (biometric, multi-factor), penetration testing, compliance documentation, regulatory audit preparation. This percentage increases for fintech applications handling sensitive financial data across multiple jurisdictions.
Testing & deployment: 10-15% of total budget.
Functional testing, security testing, performance testing, regulatory compliance testing and deployment infrastructure. Fintech apps require more rigorous testing than most applications because bugs in financial software create real financial consequences for real people.
These percentages shift based on your specific fintech product, but they give a working framework for estimating where the money goes. The cost of developing a fintech app depends on how these components balance against each other. A compliance-heavy banking app allocates more toward security, while a consumer-facing personal finance tool invests more in design.
Types of Fintech Apps and Cost Differences
The type of fintech app you’re building is the single biggest cost determinant. Different types of fintech apps carry different complexity, compliance burden and integration requirements:
Mobile banking app.
Core features include account management, transaction history, fund transfers, bill payments, push notifications and often biometric authentication. Banking app development requires heavy compliance work and deep integration with core banking systems.
Development time: 6-12+ months for a production-ready product.
These tend to land on the higher end of fintech app development costs because the regulatory and security requirements are significant.
Payment app.
Peer-to-peer transfers, merchant payments, QR code scanning, multi-currency support. Payment apps need PCI DSS compliance, integration with payment processors and robust fraud detection.
A money transfer app focused on cross-border payments adds currency conversion logic and regional regulatory layers, which affect the cost further.
The complexity here sits in the transaction engine: it needs to be fast, reliable and auditable.
Lending app.
Credit applications, risk scoring, loan management, repayment tracking, document verification. Lending apps add AI-driven credit assessment (increasingly standard in 2026, with 57% of lending platforms now using AI-driven credit scoring) and complex business logic around interest calculations, late payments and regulatory reporting.
Investment/wealth management app.
Portfolio tracking, automated investing, market data feeds, risk assessment, reporting. An investment app requires real-time data integrations, financial modelling capabilities and often compliance with securities regulations.
The data infrastructure alone can push costs significantly higher than other fintech app types. Robo-advisory features (that are increasingly expected by users in 2026) add AI model development and ongoing training costs to the fintech development budget.
Personal finance app.
Budgeting, spending analytics, savings goals, account aggregation. Generally the simplest of the fintech app types, though the account aggregation component (connecting to multiple banks via open banking APIs) adds meaningful integration complexity.
Insurance app.
Quote comparison, policy management, claims processing and document handling. Insurance apps require integration with underwriting engines and often involve complex rule-based logic that varies by product type and jurisdiction.
While less common than payment or banking apps, an insurance app can rival them in backend complexity, particularly around claims automation and regulatory reporting.
Development Process and Cost Stages
The app development process for fintech follows phases, and fintech app development costs don’t arrive all at once, they distribute across a structured development process:
Discovery & planning (4-8 weeks).
- requirements gathering;
- market research;
- regulatory mapping;
- architecture design;
- UX research.
This phase typically costs 5-10% of the total budget and determines whether everything after it goes smoothly or sideways. Skipping discovery is how development budgets double.
MVP development (3-6 months).
Build the minimum viable fintech product:
- core functionality;
- basic compliance;
- essential integrations.
The fintech MVP lets you validate the product with real users before committing the full development budget. MVP development typically accounts for 30-40% of the total cost to build a fintech app.
Iteration & scaling (ongoing).
Based on user feedback, usage data and business priorities:
- expand features;
- improve performance;
- add integrations;
- extend to additional platforms.
This phase often costs as much as or more than the MVP because the fintech product is now live and every change carries real-world consequences.
Maintenance (15-25% of initial development cost per year).
- bug fixes;
- security patches;
compliance updates; - API changes from third-party providers;
- infrastructure costs.
Maintenance is the cost that most budgets underestimate and every fintech app requires. The fintech market evolves fast and a fintech application that doesn’t evolve with it becomes a liability.
Key Factors Influencing Fintech App Development Cost
Beyond the basics, several cost drivers can shift fintech app development costs significantly:
Feature scope.
Every feature has a cost. The discipline of cutting features that aren’t essential for launch saves more money than any other single decision. Experienced fintech app developers will tell you that the most expensive feature is often the one that sounded good, but in the end nobody uses it after launch.
Custom vs. off-the-shelf solutions.
Building a custom payment engine costs ten times more than integrating Stripe or Adyen. Use existing platforms where they fit your requirements and build custom where they don’t. This single decision (where to buy and where to build) can save hundreds of thousands of dollars on a complex fintech product.
Team expertise in fintech.
A development team with deep fintech experience builds faster and makes fewer expensive mistakes. They know the regulatory pitfalls, the common integration patterns and the security requirements before writing any code. Teams learning fintech on the job cost less per hour and more per project.
Regulatory requirements.
Operating in one country with clear regulations costs less than operating across five jurisdictions with conflicting rules. Regulatory scope directly affects compliance cost, legal cost and development complexity.
Infrastructure and scalability.
A fintech app that handles 1,000 transactions per day has different infrastructure needs than one handling 1 million. Building for scale from day one costs more upfront but prevents expensive re-architecture later. Building with no thought for scale costs less now and much more when the fintech product succeeds.
Average Fintech App Development Cost Ranges in 2026
Broad ranges based on current market rates. The cost to develop a fintech app varies widely, but these categories reflect what most teams encounter:
Fintech MVP (basic app): $50,000–$150,000.
Core features, single platform, minimal integrations, basic compliance. Suitable for validating a fintech solution concept before committing serious capital.
Mid-level fintech app: $150,000–$350,000.
Multiple features, stronger security architecture, several integrations, compliance for one or two markets, responsive design across platforms. This is where most fintech startups building a custom fintech app land.
Complex/enterprise fintech software: $350,000–$700,000+.
Multi-platform, extensive integrations, advanced security, multi-jurisdiction compliance, AI-driven features, real-time data processing. Banking apps, investment platforms and enterprise-grade lending software typically fall here. At this level, the development team usually includes specialised roles like compliance engineers, security architects, DevOps, and the fintech app requires infrastructure that can handle scale from day one.
These ranges reflect development costs. They don’t include ongoing maintenance (15-25% annually), marketing, customer acquisition or operational costs. The total cost of building and running a fintech app over three years is typically 2-3x the initial development budget. Any realistic financial plan for a fintech product should account for this multiplier, because the app that launches is always cheaper than the app that runs.
Launch smarter fintech products
Talk to our experts about secure, scalable fintech app development built for modern financial experiences.
How to Reduce Fintech App Development Costs Without Cutting Quality
There’s a difference between being frugal and being careless. These strategies reduce the overall cost of building a fintech app while keeping quality intact:
1/ Start with a fintech MVP.
Build the smallest version that proves the concept works. Learn from real users and then expand. The MVP approach to fintech product development consistently delivers better outcomes than the “build everything first” approach, and it costs a fraction of the total development budget.
2/ Prioritise core features.
The app doesn’t need every feature at launch. It needs the features that solve the core problem for the target users. Everything else can wait for v2. The discipline of saying “not yet” to good ideas is the most underrated cost-saving strategy in fintech software development.
3/ Reuse existing platforms where possible.
Payment processing, identity verification, banking APIs – mature fintech infrastructure exists for most of the heavy lifting. Use it. Build custom only where existing solutions genuinely don’t fit your requirements.
4/ Avoid overbuilding early.
Multi-currency support across thirty countries sounds impressive. But if your first users are in two countries, build for two. Scale when the fintech market demands it without fantasizing.
5/ Choose the right app development company.
An experienced fintech app development company or agency with expertise in fintech will cost more per hour but less per project. They anticipate problems before they become expensive, build to regulatory standards from day one and avoid the rookie mistakes that create technical debt.
Ready to Scope Your Fintech App?
The cost to build a fintech app in 2026 depends on the decisions you make before any code gets written. App complexity, platform choice, compliance scope, team expertise, build-vs-buy decisions – these shape the overall cost far more than hourly developer rates or technology stack choices.
The cost depends on scope, scope depends on clarity and clarity is the one thing that consistently separates fintech projects that stay on budget from ones that don’t. The founders and product teams who invest time in discovery, define scope honestly and resist the urge to build everything at once consistently end up with better fintech products at lower total cost.
At Lerpal, we’ve been building fintech applications for years, from MVPs that helped startups validate their fintech solution to production-grade platforms handling real financial data at scale. We help teams define scope, estimate realistically and scale when the market asks for it.
If your current content management system is starting to feel restrictive, it often means it’s no longer keeping up with how your team works. Many marketing teams reach a point where the existing CMS slows down campaigns, limits integrations, or creates unnecessary friction in the workflow.
That’s usually when CMS migration moves from a “someday” idea to an active priority.
At its core, CMS migration refers to the process of moving your website content, structure, and functionality from one CMS platform to another. It sounds straightforward, but in practice, it touches everything like SEO, user experience, analytics, and how your team creates and manages digital content.
And the shift is already happening.
According to Gartner, over 70% of organizations are moving toward composable or modular architectures, including headless CMS approaches, to improve flexibility and scalability. That means more teams are migrating from one system to another, not just once, but as part of ongoing evolution.
At the same time, the stakes are high.
A poorly handled migration process can lead to:
- Lost search engine rankings
- Broken URLs and broken links
- Disrupted user experience
- Delays in launching new content
A well-executed one does the opposite. It helps you streamline operations, improve site performance, and create a foundation that actually supports growth.
The goal isn’t just to migrate to a new CMS.
It’s to do it in a way that creates a smooth transition, for your team and your audience.
Before you start initiating the migration process, it’s worth pausing to ask a simple question:
What do we actually need from a CMS now?
Because not all CMS platforms solve the same problems.
Understanding Why Teams Move to a New CMS
Most migrations happen because the current CMS becomes an outdated CMS, not necessarily broken, but no longer aligned with how teams work today.
Common triggers include:
- Limited integration with marketing tools
- Difficulty managing multilingual or multi-site content
- Poor site performance or slow publishing workflows
- Increasing security concerns and lack of modern security features
- Challenges when moving from a monolithic system to something more flexible
This is where modern CMS platforms, especially headless CMS options, start to stand out. They allow teams to separate content from presentation, making it easier to reuse, scale, and adapt across channels.
But switching to a new CMS isn’t just about features.
Choosing Between Different CMS Options
When evaluating different CMS options, the goal is to ensure compatibility with the new CMS, not just technically, but operationally.
Think about:
- How your team manages website content today
- What your developer team needs to support integrations
- Whether the new environment supports your future plans (e.g., personalization, omnichannel, multilingual support)
For example, moving from WordPress to a headless CMS can unlock flexibility, but it also changes how content is structured, delivered, and maintained.
That’s why a successful CMS migration starts with clarity, not tools.
Defining What Success Looks Like
A successful migration isn’t just “we launched the new site.”
It’s:
- No major drops in SEO ranking
- Clean, functional URLs and preserved metadata
- Improved user experience
- Faster workflows for creating and updating digital content
- A system that scales without constant rework
According to Stanford, 75% of users judge a company’s credibility based on website design and performance. That means your new site isn’t just a technical upgrade, it directly impacts perception and conversion.
So before you migrate to a new CMS, define what better actually looks like.
CMS Migration Checklist: What You Need Before You Start
Before you begin any CMS migration, clarity matters more than speed.
A practical CMS migration checklist at this stage isn’t about execution. It’s about making sure you have the right inputs before you migrate from one content management system to another.
Think of it as readiness.
A Clear Reason for Migration
Every migration should be tied to a specific outcome.
Whether you’re dealing with an outdated CMS, performance issues, or limitations in modern CMS platforms, the reason needs to be explicit.
Without that, it’s easy to move from one CMS to another without actually solving the underlying problem.
A Defined Migration Plan
Before touching content, you need a working migration plan.
This includes:
- Scope of the migration (full site vs partial)
- Timeline and key milestones
- Ownership across teams
- Risks during the migration period
This is what anchors your entire CMS migration process.
A Complete Content Inventory
You need visibility into your existing content before you can move content.
A proper content audit should give you:
- A full list of pages, assets, and templates
- Content types and format structures
- Dependencies between pages and components
Without this, migrations tend to introduce inconsistencies, especially when moving from one content management system to another.
Clarity on the New CMS Structure
Before you use the new CMS, you should understand how content will exist in it.
This includes:
- Content models and template structure
- How the new CMS makes content reusable or modular
- Any differences in how content is stored or delivered (especially with a headless CMS)
This is where many teams run into friction, assuming the new CMS without fully adapting structure.
SEO and Data Preservation Requirements
Even at the planning stage, SEO needs to be accounted for.
You should already know:
- What needs to be preserved from the current site
- How content, structure, and signals will carry over
- Where potential risks exist when migrating from one system
This avoids last-minute fixes during the migration process.
Tooling and Support Decisions
Not all migrations are equal.
Depending on the CMS, you may need:
- Dedicated migration tools
- Internal engineering support
- External migration services
The decision here shapes how complex, or controlled, the migration will be.
Compatibility With the New CMS
Finally, validate compatibility with the new CMS before committing.
That includes:
- Integrations with existing systems
- Support for required features and new features
- Flexibility to scale without rework
This is especially important when moving away from a common CMS or old CMS toward something more flexible.
A well-prepared checklist doesn’t slow you down.
It makes the rest of the step-by-step CMS migration predictable.
Step-by-Step CMS Migration Process
Once the groundwork is in place, execution becomes much more straightforward.
This is where the step-by-step guide comes in, not as a rigid sequence, but as a structured way to move from planning to a smooth transition.
Step 1/ Prepare and Clean Your Content
Before you move content, refine it.
Your earlier content audit now becomes actionable:
- Remove outdated or redundant content
- Standardize structure and format
- Resolve inconsistencies across pages
This reduces friction when moving from one CMS to a new one.
Step 2/ Set Up the New CMS Environment
Your new CMS should be ready before migration begins.
This includes:
- Configuring content models and templates
- Setting up required integrations
- Ensuring the environment supports your long-term needs
This is especially important with modern CMS platforms, where flexibility comes with structural decisions.
Step 3/ Migrate Content
Now you begin to migrate.
Depending on complexity, this may involve:
- Automated transfer using migration tools
- Manual adjustments for structured content
- Validation of formatting and relationships
The goal is consistency, not just speed.
Step 4/ Validate and Test
Before going live, everything should be reviewed.
Focus on:
- Content accuracy and completeness
- Layout and design issues
- Internal linking and navigation
This is where many CMS problems surface, and where they’re easiest to fix.
Step 5/ Go Live
Launching the new site should feel controlled, not rushed.
A well-executed successful migration minimizes disruption during this phase and ensures continuity across the user experience.
Step 6/ Monitor and Stabilize
After launch, the work isn’t finished.
Track:
- Site behavior and performance
- Content rendering issues
- Any gaps introduced during the transition
This final step ensures your CMS to another transition holds up in real conditions.
Launch without disruption
Move your CMS with clarity and control. Talk to our experts to reduce risk, keep momentum, and ship on time.
Common CMS Migration Challenges (and How to Avoid Them)
Even with a strong guide to a successful CMS, challenges tend to appear in similar ways.
Understanding them early makes them easier to manage.
Underestimating the Migration Process
Many teams assume CMS migration is mostly technical. In reality, it affects content, structure, and operations.
Without a clear SEO migration checklist, critical elements like URLs, redirects, and metadata are often overlooked.
This is where underestimating the cms migration process leads to delays, ranking drops, and avoidable rework.
Carrying Over Old Problems
If your old CMS had structural issues, migrating them into the new CMS doesn’t fix anything.
This is common when teams rush to migrate to a new CMS without refining content or structure.
Compatibility Gaps
Not all CMS platforms behave the same.
Differences in how content is modeled or delivered can create issues if compatibility with the new CMS isn’t fully considered early.
Design and Layout Issues
Even when content transfers correctly, layout and design issues can appear due to differences in templates or rendering logic.
These are often discovered late, during or after going live.
Overlooking the Transition Period
The migration period itself needs attention.
Running parallel systems, managing updates, and maintaining consistency across both environments can create complexity if not planned properly.
Tools and Support for a Successful CMS Migration
By the time you reach this stage, the question becomes more practical:
What do we need to execute this well?
The right migration tools don’t just speed things up. They reduce risk, improve consistency, and make the overall CMS migration more predictable.
Choosing the Right Migration Tools
Most CMS platforms offer some level of built-in support, but that’s rarely enough for a complete migration, especially when migrating from one content management system to another CMS.
Depending on your setup, you may need tools that can:
- Extract and structure content from your current system
- Transform data to match the new CMS format
- Preserve relationships between content, assets, and templates
- Support bulk operations without introducing errors
This becomes even more important when working with a headless CMS, where content modeling is more flexible, but also more dependent on structure.
When to Use External Support
Not every team needs external help, but many benefit from it.
If your migration involves:
- Large volumes of content
- Multiple CMSs or integrations
- Custom workflows or complex data structures
…it’s worth considering specialized support.
Experienced teams can help you integrate systems, avoid common pitfalls, and ensure a smooth transition without unnecessary delays.
Balancing Tools With Process
Tools alone won’t guarantee a successful migration.
What matters more is how they fit into your overall step-by-step CMS migration approach. The goal is to support the process, not replace it.
A well-structured setup ensures that when you migrate to a new CMS, everything works together: content, systems, and workflows.
A Guide to a Successful CMS Migration
At a glance, CMS migration can feel like a technical project.
In reality, it’s a structural shift in how your team manages and delivers content.
When done right, it gives you:
- More flexibility across content management system workflows
- Better performance and scalability
- The ability to adapt as your needs evolve
This is why many teams move away from rigid or outdated CMS setups toward modern CMS platforms that better support growth.
What a Successful Migration Really Looks Like
A successful CMS migration isn’t just about moving from one system to another CMS.
It’s about:
- Maintaining continuity during the migration period
- Improving how your team works day-to-day
Setting up a new CMS that supports future needs, not just current ones - Ensuring enhanced security, stability, and long-term scalability
In other words, it’s less about the move, and more about what the move enables.
A Practical Next Step
If you’ve been planning to migrate, or you’re already evaluating how to move from one content management system to another, it’s worth approaching it with structure.
This comprehensive guide gives you a clear starting point. But every migration has its own complexity, depending on your content, systems, and goals.
Lerpal works with teams to plan and execute CMS migration in a way that stays controlled, scalable, and aligned with how marketing teams actually work.
No unnecessary complexity. No disruption to your workflows.
If you’re preparing to migrate to a new CMS and want to ensure a genuinely smooth transition, it’s worth starting a conversation.
Do you often see how legacy systems fail dramatically? We neither. Because usually it takes time for them to really fail. It looks like a slow workflow here, a brittle integration there, a feature request that gets answered with “we can’t, the old system won’t let us”. And one day someone calculates how much of the IT budget is going toward keeping outdated legacy systems alive. And the room goes quiet for a minute.
It’s the IT equivalent of that moment in a horror film when someone says “I’m sure it’s nothing”. It’s always something.
When this realisation lands the instinct is to rush forward and rebuild.
Tear it all down.
Start fresh.
Build the modern, beautiful, awesome, scalable system everyone deserves.
The instinct is also expensive, risky and frequently unnecessary. According to Pegasystems’ late 2025 research, the average global enterprise wastes more than $370 million a year due to inefficient legacy modernization. Much of it is driven by transformation projects that took too long, cost too much and disrupted too much in the process.Not all the legacy systems need replacing.
Often they need a clearer path forward.
They need a modernization process that can be controlled, practical and continuous.
Not the dramatic overhaul that consumes two years of executive attention and produces results nobody can quite point to. Implementing legacy system modernization doesn’t have to mean building an application from scratch. More often it means finding the right tools and the right sequence.
Why Legacy System Modernization Matters
The hidden cost of technical debt is brutal. Gartner data suggests companies spend up to 40% of their IT budgets just maintaining technical debt, money that buys exactly zero new capabilities. In some sectors (banking, insurance, government), the figure climbs to 70–80%. That’s an entire IT operation effectively running just to stand still. Organisations that rely on outdated software are essentially paying a subscription fee for the privilege of going nowhere.
The impact compounds.
- Slow systems make scaling difficult.
- Rigid systems make integration painful.
- Outdated systems make compliance (especially under regulations that keep evolving) significantly harder.
And legacy infrastructure actively obstructs AI adoption: research shows that 68% of organisations report legacy systems holding back AI initiatives, and companies with fragmented or legacy systems are 30% more likely to experience AI implementation delays. Legacy systems can create significant challenges for businesses trying to adopt modern technologies like AI, machine learning and advanced analytics. When your data is trapped in a system that was built before the iPhone existed, asking it to power a machine learning model is like asking a fax machine to run Spotify.
There’s also the developer cost. They spend roughly 30% of their week dealing with technical debt:
- debugging legacy code;
- working around outdated systems;
- refactoring shortcuts (that someone took five years ago).
That’s a third of every developer’s week not building anything new. For a 25-developer team, that translates to nearly $1 million in lost productivity annually. Due to outdated infrastructure, entire engineering teams lose the capacity to innovate.
So legacy system modernization matters. Why? Because the cost of doing nothing isn’t zero. It’s just spread out, harder to see and growing about 20% per year.
Common Mistakes in Modernization Efforts
Before talking about what works, it helps to look at what doesn’t. The same mistakes repeat across modernization projects and they’re predictable enough to avoid:
Rebuilding too early
The most expensive mistake is also the most common one. That’s the classics diagnose a legacy problem and immediately jump to “let’s build a new one from scratch”. The new system takes 18 months, runs over budget and when it finally launches, half the original requirements have changed and the legacy system is still running anyway. Because nobody felt safe turning it off.
Proprietary software tends to come polished. The onboarding is smooth, the documentation is thorough and there’s someone contractually obligated to help when something goes wrong. That’s the deal.
Choosing tools before defining outcomes.
Modernization often starts with a vendor demo and ends with a tool nobody knew they needed. The right sequence is: identify what the business needs, define the outcome, then select the technology. Reversing that order is how you end up with three new platforms and the same old problems.
Ignoring dependencies across systems.
Legacy systems are rarely standalone. They feed data into other systems; They depend on integrations that were built years ago; They have contracts with parts of the business nobody mapped properly.
Modernising one system without understanding what it touches creates new fires while putting out old ones. System complexity in existing legacy systems is almost always worse than anyone expects.
Treating modernization as a one-time project.
Legacy modernization isn’t a project with a launch date. It’s a continuous process.
Treating an application modernization project as a single transformation initiative with a beginning, middle and end almost guarantees it’ll need redoing in five years. The systems you modernise today will be the legacy systems you modernise again later.
That’s not a failure. That’s the model. And every cycle should expand your system capabilities rather than restart from zero.
Core Modernization Strategies: Approaches to Legacy System Modernization
There are a handful of core approaches to legacy system modernization, each suited to different situations. The magic trick is matching the approach to the problem rather than picking your favourite and applying it everywhere.
Replatforming
Move the legacy application to a better platform (typically moving legacy systems to the cloud) without changing the core code significantly. This is sometimes called “lift and shift” or rehosting. Fast, lower risk and useful when the application logic is fine but the infrastructure is the bottleneck. Maintenance costs typically drop within months of moving legacy software off ageing on-premise hardware.
Refactoring
Improve the code without a full system rewrite. Restructure parts of the legacy code to improve maintainability, performance or scalability while keeping the system functionally the same. Higher engineering effort than replatforming, but it addresses problems that infrastructure changes alone can’t solve.
Wrapping
Extend the legacy application with APIs that let modern systems talk to it. The legacy system stays in place, but new applications can interact with it through clean interfaces. This is often the smartest first move, it buys flexibility without requiring you to touch the legacy code at all.
Replacing
Sometimes the legacy system genuinely has to go. The technology is unsupported, the vendor is gone, the maintenance cost has crossed a threshold where rebuilding becomes cheaper than keep-alive. Replacement is the right answer in specific situations. It just shouldn’t be the default answer.
The right legacy modernization approach often combines several of these. You might wrap one system with APIs while replatforming another and refactoring a third, all on different timelines, all aligned to different business priorities.
Different modernisation strategies suit different system needs, and any serious legacy modernisation strategy starts by mapping which approach fits which workflow rather than picking a single tactic and applying it everywhere. The application modernisation strategy that works for your payments platform is probably not the one that works for your internal HR legacy tools. And that’s fine.
A Practical Modernization Framework
Here’s a step-by-step framework for legacy system modernization that focuses on incremental progress rather than transformation theatre. Legacy system modernization means working through complexity in stages, not pretending you can solve it all in one sprint.
Step 1: Identify constraints and friction points
Start with the systems and workflows causing real pain: the ones generating support tickets, slowing releases, blocking integrations. Pain is the most reliable map of where modernization will deliver the most value.
Step 2: Prioritise high-impact workflows
Not every legacy problem is worth solving immediately. Rank workflows by business impact and modernization effort. The high-impact lower-effort items are where to start. The ones that feel impossible can wait until you’ve built momentum and confidence.
Step 3: Decouple systems before change
Before modernising anything significant, separate the system from its dependencies as much as possible. APIs, abstraction layers, integration middleware, anything that lets you change one piece without breaking three others. Decoupling work is often the most valuable thing on the entire roadmap.
Step 4: Introduce automation and AI selectively
Modern tools can reduce operational load on legacy systems, but only where they fit naturally. Automating data processing, document handling or repetitive workflow tasks frees up engineering time. Forcing AI into places it doesn’t belong creates new technical debt while solving nothing.
Step 5: Migrate gradually, not all at once.
Big-bang migrations are where modernization projects go to die. Move pieces incrementally, validate each step, keep the option to roll back. The goal is steady progress, not a launch event.
This framework is repeatable. Each cycle through it surfaces the next layer of work. Modernization stops being a project and becomes part of how the technology organisation operates.
Are your systems slowing you down more than you realise?
Most legacy systems don't need replacing, just a clearer path forward. We help you modernise without disrupting what already works.
Where AI Fits in Legacy Modernization
AI is having a moment in legacy modernization (who would have thought!) and hype can overstate what it can do. AI isn’t going to replace your legacy systems, no. It can make them significantly easier to live with and in some cases, easier to modernise.
The practical use cases:
- Data processing. AI can clean, normalise and migrate data from legacy systems faster than manual processes. For modernisation projects where data quality is the blocker (and it usually is), this matters.
- Workflow automation. AI-powered workflow tools can wrap around legacy systems and handle the manual processes that legacy interfaces force users into. The legacy system stays. The user experience around it improves.
- Decision support. AI can analyse legacy code, identify dependencies, surface patterns and flag risks during modernization planning. It won’t write your modernization roadmap for you, but it’ll help you map the territory faster.
The key thing is treating AI as a support layer. AI can’t be your replacement strategy. AI works best when it makes existing systems more usable, not when it’s bolted on to justify the project budget.
Modern technologies and automation tools should extend the capabilities of legacy apps without forcing teams to abandon what already works, and the right tools applied to the right problems can buy years of additional life from existing infrastructure.
Managing Risk, Compliance, and Continuity
The reason many companies put off legacy modernization isn’t ignorance about the cost.
It’s fear of disruption.
Legacy systems often run mission-critical processes:
- payments;
- claims;
- patient records;
- manufacturing schedules, etc.
And any modernization carries real risk. Get it wrong and you don’t just slow down, you stop. Avoiding that fate requires proper planning:
Avoid downtime
Use parallel run strategies where the new system runs alongside the legacy system for a period before fully cutting over. Yes, it’s more expensive in the short term. Yes, it’s vastly cheaper than an outage during peak business hours, which research suggests can cost large enterprises between $300,000 and $1 million per hour.
Maintain system stability during transition
Establish clear rollback procedures before you start migrating. Every change should be reversible. Every deployment should have a tested fallback. Plan for what to do when things go wrong and don’t assume they won’t.
Ensure compliance requirements are preserved
Legacy systems often carry years of compliance tuning, audit trails and certifications. New systems need to inherit all of that. Map compliance requirements before modernisation starts and bake them into the new architecture from the first sprint.
Plan for rollback and iteration
Modernization isn’t linear. Things will break, requirements will change, edge cases will appear that nobody documented. It’s part of the deal. Building rollback capability and iteration cycles into the plan makes the inevitable surprises manageable rather than catastrophic.
Best Practices for Legacy Application Modernization
A few principles that separate modernization efforts that succeed from ones that don’t:
Start small, scale what works
Pick one workflow, one system, one team. Modernise it, measure the result, document what worked and what didn’t. Then expand. This sounds obvious, but the urge to “do it all at once” is real, and it’s responsible for many of the famous modernization failures.
Build for interoperability
Whatever you build to replace or wrap legacy systems should connect to everything else. APIs, standard data formats, modular architecture. The systems you build today will be the ones that need to integrate with whatever comes next, and “whatever comes next” is now arriving every six months. A modern application that can’t talk to your existing stack is just a different version of the same problem.
Document systems as you modernise
Many legacy systems are poorly documented because the people who built them are gone, the documentation was never updated. Or both. Modernization is the rare opportunity to fix that. Document architecture decisions, dependencies, integrations and workarounds as you go. The future-you who has to modernise this again will be very grateful.
Align modernization with business goals
Every modernization decision should connect to a business outcome:
- faster releases;
- better customer experience;
- lower operational cost;
- regulatory compliance;
- AI readiness.
If a modernization initiative can’t tie back to something the business wants, it’s hard to defend, hard to fund and hard to justify when something breaks. The modernisation journey works best when each step serves the business rather than the architecture diagram.
Modernization Is An Ongoing Process
Legacy modernization isn’t a destination.
It’s a posture.
Legacy system modernization is the process of moving legacy infrastructure forward in measured steps, and the systems you modernise today will become the legacy systems of tomorrow. Treat modernization as a continuous capability.
Outdated technology rarely gets fixed by a single project. System integration work, careful migration, system optimisation these compound over time when treated as ongoing operational practice rather than transformation theatre.
Control matters more than speed.
Disruption is the enemy.
Properly sequenced and properly measured incremental progress beats heroic transformation every time.
At Lerpal we approach legacy system modernisation the same way we approach everything: practical, structured, focused on what your business needs. We help organisations identify the right modernisation approach, decouple systems carefully, introduce automation and AI where it fits and migrate without losing what works. Twenty years of building software across both legacy and modern environments has taught us that the best modernisation looks like steady, deliberate progress that nobody panics about.
Let’s talk about modernizing your systems without the rebuild.
Somewhere between “we should probably use AI” and “our entire team runs on it” there’s a gap many businesses are still crossing.
The tools are here.
But which ones are worth your time and which ones will show results six months from now?
Yes, artificial intelligence has moved past the novelty phase. Generative AI tools now handle content creation, data analysis, customer communication and business processes that used to require entire teams.
And here are some numbers.
Deloitte’s 2026 State of AI report found that worker access to AI rose by 50% in 2025, and two-thirds of organisations report productivity gains from AI adoption. And the Federal Reserve’s 2025 Small Business Credit Survey found that 71% of businesses using AI saw increased productivity.
So, the best AI tools for business in 2026 are the ones that embed into your existing business operations and make them faster without creating new problems.
How AI Tools Improve Business Productivity
AI-powered tools have moved far from the “interesting toy” phase. They automate repetitive tasks that used to eat hours:
- scheduling, data entry, first-draft writing, meeting notes;
- streamlining workflow management by connecting systems that previously required a human to copy-paste between them;
- helping teams with research, documentation and analysis at a speed that would have required hiring two extra people three years ago.
The bigger shift in 2026 is AI orchestration: combining multiple AI tools into connected stacks where the output of one feeds the input of another. Think of a meeting that gets transcribed by one tool, summarised by another, turned into action items by a third and pushed into your project management workspace automatically.
That kind of pipeline used to require custom software development. Now it takes a Zapier account and about twenty minutes.
What to Look for in AI Tools for Business
Before you commit to any AI tool, evaluate four things:
1/ Ease of integration
The best AI tools connect to what you’re already using: your docs, your CRM, your productivity apps. A tool that lives in isolation creates another silo and you probably have enough of those.
2/ Automation capabilities
Can it automate workflows and handle repetitive tasks without you babysitting it? If the tool saves you thirty minutes but requires twenty minutes of prompt engineering every time, the math doesn’t work.
3/ AI model performance
Many tools now run on advanced AI models like GPT-5, Claude or Gemini. The model underneath affects how well the tool handles nuance, follows instructions and deals with complex inputs. This matters more than the marketing page suggests.
4/ Scalability
A tool that works for three people needs to work for thirty. And then three hundred. Check whether pricing, features and performance hold up as your team grows.
10 Best AI Tools for Business Productivity
1/ ChatGPT
The AI Assistant That Set the Standard
ChatGPT has more than 900 million weekly active users, and for good reason. It handles everything from writing emails and generating reports to brainstorming ideas and automating customer support. The Business plan ($25/seat/month) adds workspace collaboration, SSO and data privacy controls. Enterprise goes further with compliance certifications, analytics dashboards and custom connectors via MCP.
For most businesses, ChatGPT is the AI equivalent of a Swiss Army knife. Not always the best tool for any single task but consistently useful across almost all of them. The GPT-5 models rolling out through early 2026 have made the reasoning and output quality noticeably sharper.
2/ Perplexity
AI Search and Research Assistant
If your team spends hours researching competitors, markets, regulations or technical topics, Perplexity changes the game. It combines AI search with real-time citations, so you get answers with sources attached. Yes, finally no more opening seventeen tabs and cross-referencing manually.
For research-heavy use cases in consulting, finance, legal or content creation, Perplexity saves time that ChatGPT alone can’t.
ChatGPT generates. Perplexity finds and verifies.
Different tools, different jobs.
The free tier is genuinely useful, and the Pro plan unlocks deeper analysis and longer research sessions.
3/ Canva AI
AI-Powered Design and Content Creation
Canva became one of the most used AI tools in business by making design accessible to people who can’t tell kerning from leading. The AI features now generate AI images, resize designs across formats, write copy and suggest layouts. Yes, all inside a tool that marketing teams were already using daily 5 years ago.
For teams producing social media content, presentations, marketing materials and internal docs, Canva AI removes the bottleneck of “waiting for design”. The free plan includes basic AI features. The paid tiers unlock the full AI creative suite, brand kits and team collaboration.
4/ Notion AI
The AI Productivity Workspace
Notion AI turns your workspace into something that thinks alongside you:
- summarises docs;
- drafts content;
- extracts action items from meeting notes;
- answers questions about your own documentation.
For teams that already live in Notion for project management and knowledge management, the AI layer makes the existing workflow faster without adding another tool.
The magic is that it operates on your data:
- your meeting notes;
- your project briefs;
- your team wiki.
Tools like Notion AI work best when they understand context and context comes from the information your team already has inside the platform.
5/ Zapier
Workflow Automation Engine
Zapier connects apps. That’s the simple version. The more accurate version: Zapier builds AI-driven workflows that automate the repetitive tasks your team does between tools:
- the copy-paste;
- the “when X happens in Slack do Y in our CRM”;
- the data routing that nobody enjoys but everyone needs.
In 2026, Zapier’s AI features have expanded to include natural language automation setup and AI-powered workflow suggestions. You describe what you want to happen and Zapier builds the automation. This is the closest thing to hiring an assistant who never sleeps, never complains and connects to thousands of apps across the ecosystem.
Are these tools actually saving you time, or just adding more to manage?
AI works best when it’s connected into how you already run your business. We help make that happen.
6/ Jasper
AI Marketing Content Creation
Jasper is built specifically for AI marketing:
- blog writing;
- ad copy;
- email campaigns;
- landing pages.
It’s trained on marketing best practices and optimised for the kind of AI content output that marketing workflows demand. Where ChatGPT is a generalist, Jasper is the specialist who knows your brand voice, your target audience and what performs. It even offers template libraries for common content types so you’re not starting from scratch every time.
If your content marketing operation produces volume like multiple blog posts per week, ad variations, social campaigns, then Jasper can handle the first draft faster than any human writer. The human still edits (please still edit), but the time from blank page to workable draft is way faster.
7/ Grammarly AI
Writing Assistant
Grammarly started as a spell-checker and evolved into something significantly more useful. The AI features now:
- rewrite for tone;
- suggest structural improvements;
- adjust formality level.
And our favorite: it catches the kind of awkward phrasing that makes professional communication feel off.
It works inside email, docs, Slack and browsers.
For teams where written communication is the default mode of work (which is most teams in 2026), Grammarly AI improves productivity by reducing the back-and-forth of “can you rephrase this?”. It’s one of those tools that’s hard to notice when it’s working and impossible to ignore when it’s not.
8/ Fireflies AI
Meeting Assistant
Open source tends to be the stronger choice when your company has engineering capability and wants control. For example:
Meetings happen. But as we all know – notes from those meetings frequently don’t. Fireflies solves this by recording, transcribing and summarising meetings automatically, then extracting action items and making everything searchable. It integrates with Zoom, Google Meet and Microsoft Teams.
The productivity gain is straightforward:
- nobody has to take notes during the meeting;
- nobody has to email the summary afterwards;
- nobody can argue about what was really decided.
Fireflies just records what happened and makes it available. For teams that run fifteen meetings a week (and we all know that’s a conservative estimate), this tool gives back hours.
9/ Claude AI

Advanced Reasoning Assistant
Claude is the AI assistant you reach for when the task requires reading a lot, reasoning carefully and not hallucinating a plausible-sounding answer. It handles long document analysis, complex writing tasks, enterprise workflows and the kind of nuanced reasoning that requires holding a lot of context at once.
Businesses use Claude for:
- contract analysis;
- research synthesis;
- technical documentation;
- strategic planning.
Where Claude tends to stand out is in tasks that require reading and reasoning over large volumes of text:
- upload a 200-page vendor contract and ask for clause-level risk flags;
- drop in a quarter’s worth of customer interviews and ask it to pull out the three themes that actually matter;
- give it a 50-tab spreadsheet export and ask for a structured summary.
These are the examples where Claude’s long-context handling earns its keep. The enterprise API and team plans offer the integration and security controls that larger organizations need.
10/ Browse AI

Automation for Data Collection
Browse AI automates web data collection without requiring anyone to write code. Point it at a website, tell it what data you want and it extracts, monitors and delivers it on a schedule. Competitor pricing, market data, job listings, product catalogues – anything that’s publicly available on the web.
For operations and research teams who currently do this work manually (or pay someone to do it manually), Browse AI turns hours of weekly data gathering into an automated pipeline. The use cases are specific but the time savings are significant for teams that depend on fresh external data.
Free AI Tools for Businesses
Not every AI tool requires a budget approval. Many of the best AI tools for business offer free tiers that let teams experiment before committing:
- ChatGPT free plan gives access to GPT-5 with usage limits. Just enough to test whether AI fits your workflow before scaling up.
- Canva AI includes basic AI features on the free plan, enough for simple design work and social content.
- Perplexity free tier handles standard AI search queries well, with the Pro plan unlocking deeper research.
- Grammarly offers a solid free version for basic writing assistance, with AI features on the premium plan.
- Notion AI integrates into free Notion workspaces, though the AI-specific features require a paid add-on.
Starting with free AI tools reduces risk. Test the workflow, measure the time saved, then decide whether the paid version justifies the investment.
How Businesses Should Use AI Tools Strategically
Collecting tools is a trap. The strategy is building stacks. Instead of adopting AI tools individually you can combine them into connected workflows where the tools work together:
- Marketing stack: Canva for visuals, Jasper for copy, ChatGPT for brainstorming and editing – content creation from idea to published asset.
- Operations stack: Notion AI for documentation and project management, Zapier for automation between systems, Fireflies for meeting intelligence – the operational backbone.
- Research stack: Perplexity for sourcing and verification, ChatGPT for synthesis and drafting, Browse AI for competitive data – research that used to take days compressed into hours.
The connective tissue matters. When your AI tools share data and trigger each other’s workflows, the productivity gains compound. When they don’t, you have ten subscriptions and the same bottlenecks. AI tools can help most when they talk to each other.
The Future of AI Productivity Tools
AI tools are moving toward autonomy. The latest AI development everyone’s watching is agentic AI: AI agents that perform multi-step tasks independently based on a goal rather than a single prompt. Deloitte found that 44% of companies were already deploying or assessing AI agents by late 2025, and NVIDIA’s 2026 report showed telecommunications leading agentic adoption at 48%.
We’re heading toward a world where your AI assistant doesn’t wait for instructions. It watches your calendar, reads your inbox, prepares your briefs and flags the problems before you ask. That world isn’t fully here yet, but the tools on this list are building toward it and the businesses investing in AI productivity stacks now will have a significant head start when agents become the standard.
How To Build AI Into Your Business?
AI productivity tools aren’t going away, and they’re not getting simpler either. The benefit comes when you choose tools deliberately, connect them into real workflows and treat AI adoption as an ongoing capability rather than a one-time purchase that will do all the work.
If you treat AI tools as isolated experiments, then you’ll get isolated results.
Integrate AI tools into your core business operations, connect the tools to your business processes and you’ll definitely report real productivity gains.
At Lerpal, we help organizations move from “we use some AI tools” to “AI is embedded in how we operate”. Whether you need help designing AI-driven workflows, building custom AI solutions, integrating AI tools into existing systems or developing an AI strategy that scales, we’ve been building this kind of infrastructure for twenty years. And AI is the latest (and arguably most interesting) layer.
Let’s talk about building AI into your business the right way.
Every piece of software your company runs sits on a decision someone made (or didn’t make) about how that software is built, licensed and maintained. Open source or proprietary. Community or vendor. Full access to the code or a subscription and a support ticket.
The choice shapes everything downstream: what you can customise, what you’ll pay over five years, who fixes things and how much control you have over the technology your business depends on.
And yet, often this choice is made by default rather than by design.
Someone picks a tool, it works, it stays and five years later you’re building your entire operation around a decision nobody remembers making.
It matters more now than it used to. 96% of commercial codebases contain open-source components, and the open source software market is growing at roughly 17% per year.
Meanwhile, proprietary software isn’t going anywhere either. SaaS revenue keeps climbing. Companies like Salesforce, Adobe and Microsoft continue to build entire ecosystems around licensed products.
So which model is better? It depends on what you’re building, who’s building it and what trade-offs you can live with. Anyone who gives you a blanket answer is selling one of the two.
The open source vs proprietary debate has the same energy as Michael Jackson vs Prince. Both brilliant, both changed the game, both have die-hard fans who’ll argue until sunrise (though we all know who sold more records).
This guide walks through both sides. What each model offers, where each one falls short and how to make a decision that fits your situation rather than someone else’s blog post.
What Is Open Source Software?
Open source software is software whose source code is publicly available. Anyone can view it, modify it, distribute it and build on top of it under the terms of an open-source licence.
The development model is collaborative by design.
A community of developers like independent contributors, companies, academics work on the same codebase, spot bugs, suggest improvements and push updates. The transparency means you can see exactly what the software does, how it does it and whether it has problems.
The open-source community behind a major project can number in the tens of thousands. Which is more eyeballs on the code than most proprietary vendors have employees.
A few characteristics that define open source:
- The source code is available and modifiable;
- Development happens through open collaboration;
- Licensing (MIT, Apache, GPL and others) governs how the code can be used and redistributed;
- Community support drives much of the maintenance and innovation.
It’s worth noting the open core model here too. Some companies release a base version as open source and sell proprietary features on top.
Redis, GitLab and Elastic have all used variations of this approach. It blurs the line between open source and proprietary. And it’s becoming more common as companies look for sustainable revenue alongside community-driven software development.
Examples of Open Source Software
You’re almost certainly using open source already. Even if you don’t think about it that way.
Linux powers the majority of the world’s servers and cloud infrastructure.
WordPress runs roughly 43% of all websites.
Kubernetes has become the standard for container orchestration.
PostgreSQL is one of the most trusted relational databases in enterprise use.
TensorFlow and PyTorch are the backbone of most machine learning development.
These open source platforms power everything from startups to Fortune 500 companies. They’ve proven that open-source software can be every bit as robust as proprietary alternatives. Sometimes more so. Thousands of eyes on the code tend to catch problems that a single vendor’s QA team might miss.
What Is Proprietary Software?
Proprietary software is owned by a company. The source code is not available to users: you get the product, but you don’t get to see (or change) how it works. Access comes through licences, subscriptions or one-time purchases.
The business model is straightforward. The vendor builds the software, controls the roadmap, provides support and charges for access. You’re paying for a finished product with dedicated maintenance, regular updates and (usually) a support team you can call.
Many proprietary products now operate as software as a service, where you pay monthly and the vendor handles hosting, updates and infrastructure. It’s convenient. Until you want to leave.
Examples of Proprietary Software
Examples of proprietary software include Microsoft Office (and the broader Microsoft 365 ecosystem), Adobe Photoshop and the Creative Cloud suite, Salesforce, Slack, Zoom. The companies behind them invest heavily in user experience, security infrastructure and feature development. And, they fund that investment through licence fees and subscriptions.
Proprietary software tends to come polished. The onboarding is smooth, the documentation is thorough and there’s someone contractually obligated to help when something goes wrong. That’s the deal.
Key Differences Between Open Source and Proprietary Software
Here’s a quick comparison of the core key differences between open-source and proprietary software:
| Feature | Open Source Software | Proprietary Software |
|---|---|---|
| Source code | Public, viewable and modifiable | Private, controlled by the vendor |
| Customisation | High – you can modify the source code | Limited to what the vendor allows |
| Upfront cost | Often free to use | Paid (licences, subscriptions, per-seat pricing) |
| Support | Community-driven; paid support available from some vendors | Dedicated vendor support |
| Control | User controlled | Vendor controlled |
| Flexibility | Adapt the software to your needs | Rely on the vendor's roadmap |
| Security model | Transparent – anyone can audit the code | Closed – vendor handles security internally |
| Vendor lock-in risk | Low | Higher |
The table is useful as a starting point. But the differences will show up in practice. In how your team works with the software day to day and what happens when your needs change.
Advantages and Disadvantages of Open Source Software
Benefits of Open-Source Software
- Lower cost. No licence fees means lower upfront spending. For startups and SMEs especially, open source tools eliminate one of the biggest barriers to getting started. The money you’d spend on software licences can go toward software development, infrastructure or hiring.
- Flexibility and customisation. When you have access to the source code, you can modify the software to fit your specific requirements. Need a feature the community hasn’t built? Build it yourself or hire someone who can. You’re not waiting for a vendor to add it to next quarter’s release.
- Community-driven innovation. Popular open-source projects benefit from thousands of contributors worldwide. Bugs get spotted quickly, features get proposed and debated and the pace of innovation can be remarkable. Kubernetes went from a Google internal project to the industry standard for container orchestration in about five years. Largely because of community momentum.
- Transparency. You can audit the code yourself. For industries with strict compliance or data privacy requirements that transparency is a real advantage.
- No vendor lock-in. If you’re unhappy with the direction an open-source project is heading, you can fork it. You always have the code. With proprietary software switching often means starting over.
Disadvantages of Open Source Software
- Requires technical expertise. Open source software is free to use. But it’s rarely free to run well. You need developers who can install, configure, maintain and troubleshoot it. For companies without in-house engineering teams that gap can be expensive to fill.
- Inconsistent support. Community support can be excellent for popular projects and nearly nonexistent for smaller ones. When you hit a critical bug, a GitHub issue doesn’t have an SLA. Nobody’s pager goes off. The community will get to it. Eventually. Probably.
- Maintenance falls on you. Updates, security patches, compatibility testing – if you’re running open source in production, your team owns all of it. Nobody else is contractually responsible for keeping it running.
- Security requires vigilance. The transparency of open source is a double-edged situation. Malicious package insertions in npm more than doubled in 2025, with over 10,800 malicious packages detected. Supply chain attacks increased 431% between 2021 and 2023 and reached a new record high in October 2025.
Open source code is safe when well-maintained, but “well-maintained” requires active effort. Using open source without monitoring your dependencies is like leaving your front door unlocked. And assuming nobody walks by.
Advantages and Disadvantages of Proprietary Software
Benefits of Proprietary Software
- Dedicated support. When something goes wrong, you call someone right away. Proprietary vendors typically offer SLAs, dedicated account managers and tiered support. For companies where downtime means lost revenue, that support structure is a must.
- Polished user experience. Proprietary software is often more intuitive out of the box. The vendor has invested in UX design, onboarding flows and documentation. Their business model depends on people using (and renewing) the product.
- Security oversight. Vendors employ security teams and handle patching, updates and vulnerability management. For companies without large security teams of their own, this offloads a significant burden. Proprietary systems often come with compliance certifications already built in. This can save months of work for organisations in regulated industries.
- Regular updates and roadmap. Proprietary software typically follows a predictable release cycle with new features, bug fixes and performance improvements handled by the vendor.
Disadvantages of Proprietary Software
- Higher costs. Licence fees, per-seat pricing, annual renewals make proprietary software costs add up. Especially as your business scales. A tool that costs $50 per user per month feels manageable at 10 users. At 500, it’s a budget line that gets scrutinised.
- Vendor lock-in. When your data, workflows and integrations are built around a proprietary platform, switching becomes painful and expensive. You rely on the vendor for pricing, feature decisions and platform direction. If they pivot, you pivot with them (or start a migration).
- Limited customisation. You get the features the vendor decided to build. If you need something different, your options are usually: request it and wait, find a workaround or buy another tool. Modifying the source code is off the table. Dependence on the vendor’s roadmap. The feature you need might not be a priority for the vendor. And if the vendor gets acquired, changes pricing or discontinues a product, you’re navigating that disruption whether you planned for it or not.
Open Source vs Proprietary Software for Businesses
When Open Source Makes More Sense
Open source tends to be the stronger choice when your company has engineering capability and wants control. For example:
- Startups with development teams who can configure and maintain their own infrastructure;
- Companies building custom platforms where off-the-shelf proprietary products don’t fit the requirement;
- Organisations that need deep customisation, integration flexibility or the ability to move fast without waiting for a vendor’s release cycle.
Open source also works well as foundational infrastructure where the technology is mature, widely adopted and backed by large communities and commercial support options.
When Proprietary Software Makes More Sense
Proprietary software often wins when speed of deployment matters more than deep customisation. For example:
- Businesses that need a working solution quickly and don’t have the engineering team to build or maintain open-source alternatives;
- Companies where the core competency isn’t technology (think a law firm, an accounting practice, etc.) and the priority is using software that works reliably without thinking about it.
- Organisations in regulated industries where vendor-backed security certifications, compliance documentation and dedicated support are requirements.
Ready for software that scales?
Talk to our experts about open source and proprietary options built for reliability, flexibility, and long-term growth.
The Hybrid Approach: Combining Open Source and Proprietary Software
In practice, most modern companies don’t pick one side but run a mix.
Open-source infrastructure (Linux servers, Kubernetes for orchestration, PostgreSQL for databases) combined with proprietary SaaS tools for specific functions (Salesforce for CRM, Slack for communication, Figma for design) alongside custom internal software built on open-source frameworks;
This hybrid strategy lets companies optimise each layer independently. Use open source where flexibility and control matter most. Use proprietary tools where the vendor’s polish and support save time and build custom where no existing software product fits.
The 2025 data from Mordor Intelligence supports this pattern: 96% of organisations maintained or expanded their open source use while simultaneously spending more on proprietary SaaS. The two aren’t competing. They happily coexisting. Whether open source or proprietary, the tool earns its place by solving a problem.
The hybrid approach also hedges risk. If a proprietary vendor changes pricing or gets acquired, your core infrastructure still runs on open source tools you control. If an open-source project loses momentum or community support, your business-critical workflows are still backed by proprietary vendors with SLAs.
Spreading your dependencies across both models gives you options and in technology options are worth a lot.
How Businesses Should Choose the Right Software Solution
There’s no universal answer, but there is a useful framework for thinking it through. Evaluate five things before you commit:
- Technical expertise. Do you have engineers who can manage open-source tools in production? If yes, open source gives you more control. If not, proprietary solutions with vendor support might be the safer starting point.
- Scalability needs. How will your software needs change as you grow? Open source offers flexibility to scale on your terms. Proprietary software often scales predictably but at increasing cost.
- Budget reality. Open source saves on licences but costs in engineering time. Proprietary software costs more upfront but may reduce maintenance overhead. Calculate the total cost of ownership.
- Security requirements. Both models can be secure. Open source requires active security management and dependency monitoring. Proprietary software offloads security to the vendor but you’re also trusting the vendor with less visibility into how they handle it.
- Customisation needs. If your business requires software that behaves in specific ways that off-the-shelf products don’t support, open source or custom development is the path. If standard features cover your needs, proprietary tools get you there faster.
The right answer usually involves weighing these factors against each other, against the specific product you’re building, the team you have and the timeline you’re working with.
Making the Right Choice
Open source and proprietary software each solve real business problems. Open source gives you transparency, flexibility and control. Proprietary software gives you polish, support and speed. Most businesses end up using both and are deliberate about where each model fits.
The decision matters because it affects your costs, your team’s capacity, your ability to customise and your long-term independence. Getting it right requires understanding what your organisation needs and being honest about what it can maintain.
At Lerpal, we’ve spent twenty years developing software solutions across both worlds. We help companies evaluate what makes sense for their context, design architectures that combine open source and proprietary tools effectively and build the custom software that ties it all together.
Whether you’re choosing a stack, migrating between platforms or building something entirely new – we’ve done it before and we’d be happy to do it with you.
Let’s talk about building the right software solution for your business.
AI adoption is accelerating. Good AI and AI strategies? Much less so.
McKinsey’s 2025 Global Survey found that 88% of organisations now use artificial intelligence in at least one business function. At the same time, only about 7% have fully scaled it. MIT’s research went further: roughly 95% of generative AI pilots deliver zero measurable return on P&L. Thirty to forty billion dollars of enterprise investment and the vast majority of it stuck in pilot purgatory.
So the technology works and adoption is real, but somewhere between “let’s try AI” and “AI is generating business value” something keeps breaking. Repeatedly. At scale. With impressive budgets attached.
That something is AI strategy.
Enterprise AI strategies determine whether AI becomes a capability your organisation can build on or an expensive experiment that gets shelved next quarter when someone asks “wait, what did we get from this?”.
Good AI, the kind that aligns with business goals, scales and creates measurable value that is an outcome of disciplined execution. And discipline, as it turns out, is harder to buy than a language model subscription.
Here are 8 enterprise AI strategies that separate the 5% from everyone else.
1. Business-First AI Strategy
Before anyone picks an AI model or evaluates AI tools there’s a question that deserves an answer: what core business problems are we solving?
Good AI strategies starts with clarity on priorities, growth objectives, margin pressures, risk exposure and customer outcomes. If an AI initiative can’t trace a direct line back to your business objectives and corporate strategy, it probably shouldn’t be funded.
That sounds ruthless, but consider the alternative: MIT’s research found that over half of enterprise AI budgets go to sales and marketing tools (the most visible category) while back-office automation consistently delivers higher ROI.
Investment follows hype when business strategy isn’t leading the conversation. And hype, for the record, has never once appeared on a balance sheet as an asset. Align AI strategies with what the business needs and only then choose the technology. The sequence feels obvious but the number of organisations that do it backwards suggests otherwise.
2. Use-Case Prioritisation Strategy
There are always more AI use cases than time, budget or patience to implement them. Always. The 2025 AI Governance Benchmark Report found that 80% of enterprises have fifty or more generative AI use cases in their pipeline. Most have only a handful in production.
The gap between “ideas” and “shipped” is where enterprise AI goes to age.
Leading organisations sequence their AI initiatives deliberately. They identify high-impact domains, pick the ones with the best ratio of effort to business value, prove those work and build momentum from there. Scattered experimentation is how you end up with twelve AI projects, three conflicting analytics dashboards and a proof-of-concept that nobody remembers commissioning. Every one of those projects has a Slack channel, a project lead and a monthly update meeting. None of them have shipped.
Good AI is curated. Pick a boring expensive problem, automate it, measure what changed and then expand.
3. AI Operating Model Strategy
Structure determines whether AI scales or stalls, and this is where many enterprises hit a wall that has nothing to do with technology. Good AI strategies involve getting the operating model right before scaling anything.
An AI operating model needs to define decision rights, accountability, funding authority and cross-functional coordination:
- Who approves new AI projects?
- Who owns outcomes after deployment?
- Who decides when to kill something that isn’t working?
Without clear answers, AI initiatives drift into the organisational equivalent of a shared Google Doc where everyone has edit access and nobody owns the final version. And the longer ownership stays unclear, the worse it gets. Projects duplicate because nobody knew someone else was already doing the same thing. The waste isn’t dramatic but administrative, and that’s why it survives so long without anyone noticing.
The typical options are centralised (one team controls everything), federated (business units run their own AI) or hybrid. Each has tradeoffs.
- Centralised models offer consistency but can bottleneck every decision through a single team that becomes the busiest people in the building;
- Federated models move faster but risk duplication: three teams building three chatbots for three slightly different versions of the same problem;
- Hybrid approach tries to balance both and (like most compromises) works best when the governance framework around it is solid.
Pick one, define the roles, revisit as AI maturity grows. The worst choice here is no choice because ambiguity doesn’t pause while you figure it out, it just creates more pilots.
4. Governance and Responsible AI Strategy
Governance gets a bad reputation. People hear the word and picture slow approvals, thick policy documents and “compliance” repeated until it loses all meaning, but in the AI context governance is what keeps things from going wrong in expensive and public ways.
The PEX Report 2025/26 found that only 43% of organisations have a formal AI governance policy in place, while 29% have none at all. Meanwhile, Deloitte’s 2026 State of AI report found that only one in five companies has a mature governance model for autonomous AI agents, even as agentic AI adoption accelerates quickly. That’s like building faster cars while removing the brakes. Technically impressive, strategically questionable.
Responsible AI means embedding data controls, ethical AI, compliance oversight and model monitoring into how AI systems operate from day one.
- Address ethical risks before they become headlines.
- Establish data protection standards before a regulator asks about them.
- Monitor AI outputs continuously, because a model that worked well in January might hallucinate confidently by March.
Governance done well is the reason you can deploy without worrying that something is going sideways. Governance done badly (or not done at all) is the reason your competitor is in the news for the wrong reasons.
5. Data and Technology Foundation Strategy
AI cannot outperform its foundation. You can deploy the most sophisticated machine learning models available, and if they’re trained on messy, incomplete or contradictory data, the AI outputs will reflect exactly that. Garbage in, confident garbage out!
Data quality, interoperability, infrastructure scalability and platform standardisation is the groundwork that separates robust AI from expensive disappointment. And you can’t redesign business processes on top of fragmented, siloed data. If data lives in four systems and disagrees with itself in three of them, your AI will confidently act on whichever version it sees first or likes more. It won’t ask for clarification, it will just be wrong, fluently.
This also means managing data governance alongside AI governance.
- Know where your sensitive data lives;
- Know who can access it;
- Know which data your AI systems are training on.
When you skip this step, you tend to discover the problem later, usually in front of a regulator or on the front page of something you’d rather not be on.
Data preparation typically consumes 40-60% of AI project budgets and up to 70% of data science teams’ time. That ratio feels backwards until you’ve watched a perfectly capable AI system produce nonsense because nobody cleaned the inputs.
6. Talent and Capability Development Strategy
Insufficient worker skills is one of the biggest barriers to integrating AI into existing workflows. The technology is ready but the people strategy, in many cases, is only catching up.
AI maturity is organisational maturity. It means:
- AI literacy across leadership (not just the data science team) so that executives can evaluate AI initiatives without defaulting to “sounds impressive, approved”;
- Technical depth in core teams so engineers and analysts can work alongside AI systems rather than route around them;
- Continuous up skilling, because AI tools evolve so fast that last year’s training is already a historical document.
McKinsey’s data shows that high-performing organisations are three times more likely to report strong senior leadership engagement with AI. That engagement goes beyond signing off on budgets. It means leaders who role-model use of AI set the vision and make governance decisions rather than delegating them into a committee that meets every other Thursday.
Successful AI strategies were driven by empowered line managers, not centralised AI labs. The people closest to the problems usually know which problems are worth solving. Give them the skills and the permission to use AI and adoption stops being a top-down mandate and starts being something that sticks.
Build AI you trust
Talk to our experts to shape a practical, governed AI strategy that scales safely and delivers real outcomes.
7. Portfolio and Investment Strategy
AI investments should be managed the way any serious portfolio is: with balance, discipline and regular rebalancing.
That means:
- Allocating across efficiency gains and growth initiatives;
- Short-term ROI and long-term positioning;
- Incremental improvements and entirely new AI capabilities;
- Courage to defund things that aren’t working which is harder than it sounds when someone’s reputation is attached to a pilot that’s been running for nine months with no clear key performance indicators.
8. Dynamic Iteration and Change Strategy
An enterprise AI strategy written in 2025 and left untouched by 2027 will be irrelevant. Markets evolve, technology follows. Your strategy has to keep pace or it becomes a very well-formatted artifact from a different era.
- Establish review cycles;
- Build performance tracking into every initiative from the start;
- Create feedback loops where the people using AI tools can report what works, what doesn’t and what’s changed since deployment;
- Build capital reallocation mechanisms so budgets follow performance rather than staying locked to last quarter’s plan.
If you still review their AI strategy annually, you are reviewing a document that was outdated by the time the meeting started.
The best enterprise AI strategies treat iteration as a feature. Getting it right the first time is a fantasy, but getting better continuously is how AI success happens.
A Practical Framework for Creating Good AI
If the eight strategies above feel like a lot (and they are), here’s the condensed version. Five steps to create an effective AI strategy:
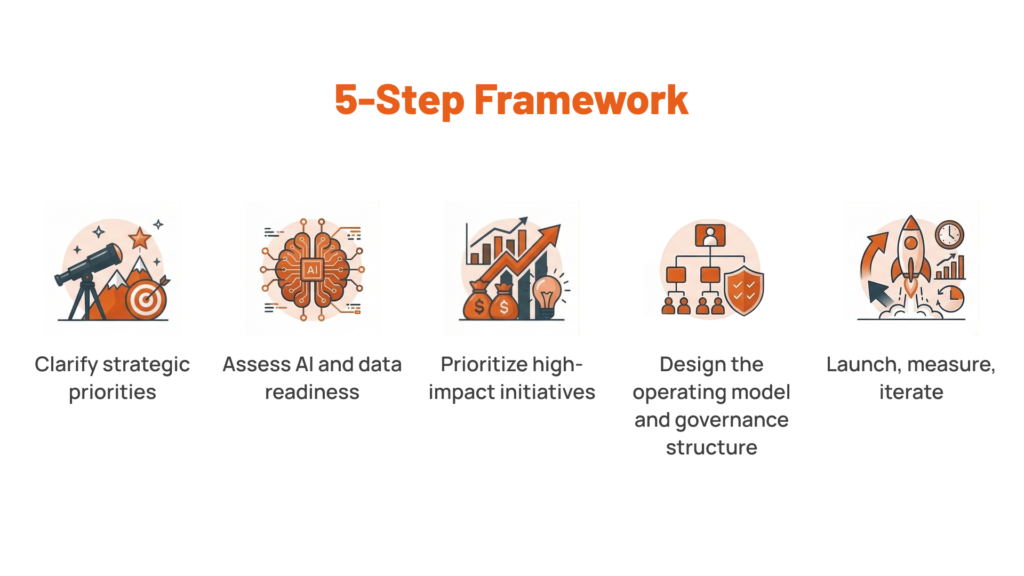
This won’t win awards for novelty. But if you follow it step by step without skipping the boring parts, you will end up on the right side of that 95/5 divide.
What Comes After Strategy
Enterprise AI strategies fail because there are too many pilots without ownership, too much investment without alignment, too much technology without architecture, too much enthusiasm without a governance framework. The patterns are well-documented. That 95% failure rate is alarming, but it’s also useful because it tells you exactly what to avoid.
Good AI is the outcome of everything that comes before the model: the business alignment, the operating model, the data foundation, the talent, the governance, the portfolio discipline, the willingness to iterate. Get those right and the AI part becomes the relatively straightforward part.
At Lerpal, we approach AI strategy the way we approach everything: architecture first, execution always. We help organisations build the conditions for AI to work the operating models, the data infrastructure, the governance structures, the delivery capability so that when AI enters the picture it has somewhere solid to land.
Good AI comes from better foundations. And foundations, as it happens, are what we build.
Explore how Lerpal helps organisations create the conditions for AI that works.
Your operating model isn’t broken. It’s just slowing everything down.
Nobody ever announces this in a meeting. There’s no crash, no siren, no Slack thread titled “Our operating model broke”. Instead things just take longer. Approvals multiply.
Handoffs get complicated.
A two-week task takes two months.
And everyone blames “the process” without noticing that the process is the operating model.
It’s like boiling a frog, except the frog is your delivery speed and the water is governance.
Here’s a distinction worth tattooing somewhere visible: your business model is how you make money. Your operating model is how you deliver value. One lives in investor decks, the other lives in calendars, sprint boards and approval chains.
They’re related, but they’re not the same, and the second one is where organisations lose their edge.
McKinsey’s research found that even top-performing companies achieve only about 70% of their strategies’ full potential. Operating model shortcomings are a major reason.
Almost a third of your strategic value left on the table.
A Quick Stress Test Before We Go Further
Before we dig into why operating models fail and what makes them work, try this. Five questions. Be honest (nobody’s grading).
- Does your operating model accelerate delivery or slow it down?
- Are you funding projects or products?
- Do teams own outcomes end-to-end? Can you ship weekly without executive escalation?
- Does your tech architecture support your organisational structure?
If most answers were “no” or “not really” then keep reading. If all answers were “yes”, then also keep reading. Confidence is sometimes the last thing to go before reality hits.
What Is An Operating Model?
An operating model is the blueprint for how an organisation delivers on its business strategies. It connects organisational structure, governance, business processes, technology enablement, talent and decision rights into something that (ideally) works together.
Think of it as the organisational architecture behind your value proposition, the thing that turns strategy into output. Or, less charitably, the thing that sometimes turns strategy into meetings about strategy.
Operating model examples come in different shapes.
- A centralised model keeps decisions and resources tightly controlled at the top: consistent, efficient, sometimes slow.
- A product-based model organises around products or customer segments, giving teams more autonomy and agility.
Neither is inherently better. The right one depends on what you’re delivering and how fast the market around you is moving (spoiler: probably fast).
Then there’s the gap between where you are and where you want to be:your current state versus your target operating model.
The current state is how things work today:
- The real workflows;
- The real bottlenecks;
- The real decision paths;
- The meetings that could have been emails.
The target operating model is the designed future state aligned with your strategic objectives. Most organisations have a version of both. The trouble starts when nobody measures the distance between them honestly.
Why Most Operating Models Fail?
Operating models don’t burst into flames on a Tuesday, they erode. A layer here, a committee there, an approval step that made sense once but now adds a week to every decision.
And then someone asks “Why does everything take so long?” and nobody has a good answer.
McKinsey’s research on operating model redesigns paints an interesting picture. 63% of companies have met most of their transformation objectives. Sounds reasonable until you realise that only 24% were highly successful. And that’s actually an improvement over a decade ago.
The failures tend to follow a few familiar patterns.
They’re designed for control, not speed
Operating model work starts with good intentions: let’s create clarity, let’s define governance. But governance has a gravity problem, it accumulates.
More approvals, more committees, more people who need to say “yes”. McKinsey emphasises that a well-designed model should accelerate execution, not add layers of friction.
Yet many organisations optimise for risk avoidance over productivity and then wonder why their competitive advantage is doing a slow moonwalk off the stage.
They ignore technology reality
Organisational charts can be redesigned in a workshop, but legacy systems cannot. A new operating model might call for cross-functional squads and seamless data-driven collaboration. But if your tech stack is a collection of siloed systems held together with custom middleware and good vibes, the org design is already disconnected from reality.
As Deloitte’s research on technology operating models puts it, legacy systems, traditional project management techniques and complex integrations all pose direct challenges to organisational delivery speed. And most technology organisations are still stuck in that hybrid state, caught between old infrastructure and new ambitions.Teams are told to streamline and collaborate, then discover they can’t share data between departments without filing a request and waiting three days.
“Customer-centric” is declared, not designed
Almost every operating model redesign includes one “We will be customer-centric” (right between “digital transformation” and “continuous improvement” on slide fourteen).
But customer-centricity isn’t a declaration. It requires cross-functional squads with shared metrics, aligned incentives and ways of working that put customer segments at the centre, not business units. If marketing and sales can’t see what engineering is doing (and vice versa), the customer-centric slide is just a slide.
The roadmap is strategic, but not operational
Big vision, ambitious strategic objectives, beautiful three-year roadmap. And then no sequencing, no delivery engine, no clear answer to “What ships next week?”. A roadmap without an operational model underneath it is just a wish list with better formatting.
Build models that hold
Most operating models drift as complexity grows. Align structure, decisions, and execution. Talk to our team to make it work in practice.
The 4 Key Components That Make Operating Model Work
Enough about what breaks. Here’s what makes the operating model work land, and not in theory, but in the calendar-and-code reality of delivering products.
1. Clear decision ownership
Not “everyone is responsible”. When everyone is responsible then nobody is, this is not a group project in school. Define who can say “yes”, who can say “no” and who doesn’t need to be in the room. Decisions are faster when fewer people have veto power and more people own outcomes.
2. Product-based delivery structure
Organise around products and customer outcomes, not departments. The difference between “the dev team builds what the business team requests” and “a cross-functional team owns this product end-to-end” is the difference between a relay race and a football team. One hands off, the other adapts in real time.
3. Embedded engineering
Not outsourced thinking, but engineering as part of the operating model’s core. When tech teams understand business processes deeply enough to challenge assumptions (not just execute tickets), the whole organisation moves differently.
4. Scalable DevOps and QA automation
An effective operating model treats infrastructure and quality as accelerators rather than afterthoughts. If every release requires a manual testing marathon and a prayer to the deployment gods, your model has a delivery bottleneck baked in.
These four components work together. Remove one and the rest compensate for a while, then the whole thing starts to drift like a shopping cart with one bad wheel.
What A Target Operating Model Looks Like
Where is the way of getting real value from AI? A real target operating model is not a diagram with boxes and arrows that people present once and filed somewhere between last year’s OKRs and that brand guidelines doc nobody opens. A working one:
- Aligns organisational structure with technology architecture;
- It funds products, not projects, meaning teams have continuity and ownership rather than being assembled and dissolved every quarter like a band that keeps breaking up and reuniting;
- It measures customer outcomes and it enables faster iteration because the people, the processes and the tech stack are designed to support each other.
This is where the execution layer matters. Modern backend scalability, DevOps and SRE practices, QA automation, product-led delivery models, agile execution support these are no buzzwords but the infrastructure underneath an operating model that delivers. Without them even the most elegant organisational design stalls at implementation.
At Lerpal, this is exactly the kind of operating model work we support by embedding engineering, DevOps and delivery capability into the model itself. Because an operating model that looks right on paper but can’t ship weekly is just a governance upgrade with better formatting.
What Breaks Still Needs Fixing
Operating models fail because nobody’s watching the right symptoms. The meetings get longer, teams get frustrated when you name it, and everyone assumes it’s a people problem or a process problem when it’s actually a model problem.
The operating model describes how your organisation turns strategy into delivered value. When it works, it’s nearly invisible. When it doesn’t, everything feels harder than it should.
If your operating model is clear on paper but slow in practice, it’s an execution architecture problem, and good news, that’s a solvable one. Explore how Lerpal helps organisations align delivery, engineering and operating model design.
Somewhere right now, a company is launching an AI pilot. There’s a presentation deck, there’s excitement and a vague promise to “transform your life”. In about six months, that pilot might just disappear. Why?
Well, this happens constantly. MIT’s study on enterprise AI found that roughly 95% of generative AI pilots fail to deliver measurable financial returns. Not “underperform” – fail. The researchers analysed 300 public AI deployments and interviewed 350 employees across industries and the pattern was consistent: companies launch AI projects with enthusiasm, then watch them stall before reaching production.
The problem usually has nothing to do with the technology itself. AI integration works fine when set up properly. The issue is the way companies try to use it: the planning, the rollout, how they manage change and whether they’re honest about what it actually takes to make it work.
If you’re in media, publishing or fintech (industries where AI integration is now table stakes), understanding these patterns might save you a lot of money and frustration.
The Pilot Trap
The most common AI integration mistake is treating pilots as progress. Companies run small experiments, see promising results in controlled conditions, then assume the hard part is over but it rarely is. Getting from “this works in a lab” to “this runs smoothly every single day” takes way more work than expected.
According to S&P Global’s report on AI in banking, only 5% of integrated AI pilots have been scaled into actual workflows. The gap between demonstration and deployment is where AI initiatives die. The reasons cited include models that can’t adapt to real-world complexity, organisational resistance and (perhaps most importantly) nobody clearly owning the outcome.
When everyone is responsible for an AI integration project, no one actually is. Without someone clearly owning it, pilots just become endless experiments that eat up budget but never deliver results.
INMA, which helps news publishers adopt new technology, found a related problem: companies often ask employees what they think about AI tools only after they’ve already bought and installed them. That turns the whole thing into a sales pitch instead of actual change management. People reject tools they weren’t asked about. Obvious when you think about it but ignored way too often.
Building the Platform Before Proving It Works
Another expensive mistake: trying to build an AI integration before you’ve proven AI works for one specific thing.
The urge to build a big reusable platform feels smart from a tech perspective, but it’s a disaster for actually getting results. Companies want to build frameworks that work everywhere, shared tools, fancy infrastructure. Technically, that makes sense. But from a business perspective, it spreads the impact so thin that nobody can see any real benefit.
Start narrow. Automate one boring process, speed up one approval workflow, prove that works and then expand. This creates real wins that justify spending more money and make people believe AI helps.
Publishing companies learned this lesson the hard way. The Chicago Sun-Times published a summer reading guide in May 2025 that listed 10 completely made-up books created by AI. The CEO later called it turning the paper into “the poster child of ‘What could go wrong with AI?'” These failures happen when companies use AI for important stuff before they’ve figured out basic quality checks.
The Data Question
Data quality accounts for 43% of AI project failures and this problem is worse in industries with fragmented systems. Media companies typically run content across multiple CMSes, ad platforms, analytics tools, audience databases. Fintech companies deal with legacy banking infrastructure, regulatory systems, third-party integrations. Getting clean, consistent data from these environments requires work that nobody finds exciting and often it just doesn’t get done.
The World Economic Forum made this point in: “Imagine your customer relationship manager and enterprise resource planning system both contain the same contact. In one system, they are a customer; in the other, a supplier. The email addresses match but one record includes a middle initial and the other doesn’t. Which record is correct? Which system is the source of truth? And which version does your AI act on?”
This is what enterprise AI looks like in practice. Success means fixing your data problems before you worry about fancy AI models. The smartest AI in the world will give you garbage results if you feed it messy, incomplete, or wrong data.
Letting AI Run Wild Without Supervision
The Federal Reserve Bank of Richmond published research showing that banks with higher AI intensity incur greater operational losses than those using less AI. The relationship was driven by three areas: external fraud, problems with customers and system failures.
This doesn’t mean AI is bad for banks. It means AI without proper oversight creates new problems and makes existing ones worse. The research found these issues were especially bad at banks with weak oversight.
Publishing has the same pattern. When you let AI handle important editing work without enough human review, it makes terrible mistakes: deleting whole paragraphs, changing punctuation in ways that flip the meaning or just making stuff up.
World Economic Forum research found that 66% of employees trust AI output without checking it, and 56% say they’ve made mistakes at work because of it. Shall we all just avoid AI in work processes? No, we need to build verification into the process from the very start.
Turn AI into results
Avoid costly missteps with clear scope, clean data, and strong ownership. Talk to our experts to build it right.
What Works Then?
Where is the way of getting real value from AI?
Start with a specific problem, focus on technology later. Start with “we waste 10 hours a week doing this thing”. Focus on specific problems where you know exactly what AI will do, who it helps and how you’ll measure if it worked.
Say “yes” to: “Our support team spends half their time answering the same five questions over and over”.
Say “no” to: “We need an AI strategy”.
Assign clear ownership. Someone needs to be responsible for both setting it up and making sure it works. MIT’s research found this was one of the biggest differences between projects that succeeded and ones that failed.
Partner rather than build from scratch. Purchasing AI tools from specialized vendors succeeds about 67% of the time, while internal builds succeed only one-third as often. This matters especially in regulated industries like finance, where many companies are building their own systems even though buying works better. The urge to build everything yourself usually comes from wanting control or thinking you’re special (you are though). But unless AI is your main business, you’re better off buying from experts who’ve already figured out the hard stuff.
Invest in people, not just technology itself. AI projects succeed or fail based on whether your company is ready for them, not how advanced the technology is. Many failures come from bad planning and poor change management. This means training people, managing change, explaining what’s changing and why and involving the people who’ll use the tools in deciding how they work. Many spend 90% of their AI budget on technology and 10% on helping people adapt. Try to flip that around.
Take your time. Your productivity might actually drop at first when you start using AI. Major changes to how work gets done take time to pay off. Follow a careful pace: prove it works in one area over 3-6 months, write down what you learned, then expand step by step instead of trying to change everything at once.
The Bottom Line
Failures follow predictable patterns: trying to do too much at once, moving too fast, ignoring data problems, skipping human oversight and treating test projects as if they’re finished products.
The 95% failure rate sounds scary, but it’s actually helpful, you don’t have to make these expensive mistakes yourself. The patterns are clear and the solutions are known. Approach AI with patience, clear objectives and realistic expectations. The technology works. Is the organisation around it ready?
Read our articles on other topics:
Privacy-First AdTech And What To Wait From It in 2026?
CMS Migration Challenges: What Goes Wrong And How to Avoid It
There’s that thing about conversations about CMS architecture and ad revenue they usually start in the wrong place. They focus on features: does this platform have a paywall integration, does that one support AMP, but the impact also sits in decisions that seem just technical until you watch them drain (or boost) your CPMs month after month.
If you strip the jargon away, it’s simple: your CMS influences how fast pages load, how long people stay and how quickly you can test improvements. And those three things show up in revenue.
Page Speed: The Foundation
Let’s start with the obvious one that sometimes is getting ignored. According to Statista, 46% of people will leave a website if it takes longer than 4 seconds to load on mobile. When sites load in just 1 second, only 7% of visitors leave, but this nearly doubles to 13% at 2 seconds. The probability of abandonment increases by 32% for pages loading between 1 and 3 seconds.
These seconds are basically one “hmm” and one swipe.
Now connect that to advertising slow-loading sites lose readers and ad impressions. It loses viewability and viewability affects what advertisers are willing to buy. If your page loads like it’s auditioning for 2012, the ad stack doesn’t get nostalgic, no, it just pays less. Publift’s viewability guide gives a very concrete example: “Telstra will pay a very high CPM for viewability over 70%. It’s a key metric for their business goals.” – CJ De Guzman, Business Analyst. So, if your average ad viewbility is below 50%, you may be excluded from premium campaigns altogether.
The CMS connection here is direct: your architecture determines how fast pages render and how reliably they behave under load. A tightly coupled CMS (where everything content, design, and data processing happens in one place) can struggle under spikes. A well-architected one? Smooth criminal.
Core Web Vitals made this performance gap easy to track. According to the HTTP Archive CrUX Report analyzed by DebugBear, 49.7% of websites passed Core Web Vitals on mobile and 57.1% passed on desktop. That’s progress, but it also means roughly half the web is still leaving money on the table. Which is a polite way of saying: many sites are still donating revenue to the void.
For publishers, this translates directly to revenue: slower pages usually mean fewer pages per session, fewer ads seen and weaker overall yield.
The Session Time Multiplier
Ad revenue is a multiplication problem. Total impressions roughly equal visitors × page views per visitor × ads per page. CMS architecture mostly affects the middle term: how many pages someone reads before they leave. The “one more click” is where money lives.
This goes beyond raw speed. A CMS that makes internal linking easy enables strong recirculation modules and supports content hubs tends to increase session depth. Not because it’s “magical,” but because it removes friction from editor workflows and makes the site better at guiding people forward.
And the opposite is also true: when these things require developer help every time, teams do less of it. The site gets flatter, sessions get shorter and revenue follows. Nobody wakes up excited to file a ticket for “please add related links”.
A/B Testing: Architecture Meets Optimization
Here’s where CMS architecture starts creating measurable lifts: experimentation. The ability to test headlines, layouts, ad placements and content formats depends entirely on what your platform allows. If every test feels like a mini migration, you stop testing.
A well-documented historical example comes from Harvard Business Review: a change to ad headline presentation at Microsoft Bing, once tested, led to a 12% increase in revenue worth over $100 million annually in the U.S. The idea had been shelved for six months before an engineer decided to just test it.
Overall, some research shows companies using systematic A/B testing grow revenue faster and tests can boost conversion rates by 49%. A CMS that supports experiments natively (or integrates cleanly with testing tools) shortens the loop: you test, learn and ship improvements continuously. A rigid system turns each test into a mini-project and the optimization habit dies. Fast feedback loops beat heroic one-time efforts.
Publishers can test ad placement, ad density, layouts, formats and even where ads appear relative to content but only if the platform makes iteration safe and fast.
Unlock higher AD yield
Your CMS shapes speed, layout control, and ad delivery. Refine it to lift viewability and revenue.
Breaking News and Traffic Spikes
News publishers have a unique architectural headache: traffic is unpredictable. A major story can multiply visitors dramatically, within hours and your CMS either holds or falls over. And it usually picks the worst possible moment to get weird. That matters for revenue in two ways:
First, if the site goes down, you lose impressions during your highest-demand window.
Second, even when the site stays up, performance degradation hurts viewability and page depth right when you’re getting the most eyeballs.
Cloud hosting, caching strategies and architectures that separate content management from content delivery all help here. The goal is a system that performs under pressure.
The Ad Stack Integration Problem
Modern publisher monetization is a crowded stack: header bidding, multiple SSPs, consent management, lazy loading, refresh rules, and performance constraints. Your CMS needs to accommodate all of this without turning each integration into a six-month rebuild.
Opti Digital’s publisher A/B testing write-up is a good reminder of what teams test: partners, formats, placements, lazy loading behavior (to protect Core Web Vitals), ad density and more with success judged by RPM, viewability, latency and fill rate.
The architecture question: can you add or adjust ad logic without redeploying the entire site? Can editors preview content with realistic ad behavior? Can you tune ad refresh without crushing performance? These are the platform questions, and they’re the difference between “we’ll try it” and “we’ll never touch that again”.
The Headless Question
Headless CMS architectures have gained traction among publishers and the performance case can be real: decouple content from presentation, deliver through fast CDNs, ship leaner frontends. When it’s done well, it’s genuinely nice.
But can we keep the market numbers accurate? Market projections for headless CMS vary significantly across research firms a sign that this is still an emerging market with different measurement methodologies: Market Research Future projects the headless CMS software market to grow from USD 3.95B in 2025 to USD 26.66B by 2035, at a ~21.04% CAGR (2025–2035). Other analysts project different ranges Future Market Insights projects the headless CMS software market to grow from approximately to USD 7.1 billion by 2035, at a CAGR of around 22.6%
The ad-revenue angle: faster delivery and cleaner rendering can help viewbility and session quality. Headless also makes omnichannel delivery easier (web, apps, etc.), but headless requires solid implementation. A well-optimized traditional CMS can outperform a poorly implemented headless build. The “right” choice depends on your team and your reality.
The Migration Reality Check
The software outsourcing market isn’t slowing down. The global outsourcing market generated $854.6 billion in 2025 and is projected to reach $1.11 trillion by 2030. The custom software development segment is growing at around 22.5% annually. Companies are increasingly turning to external teams because internal hiring can’t keep pace, about 81% of companies report tech worker shortages, per Mind Inventory’s 2025 statistics.
The companies that figure out how to build lasting partnerships will have a significant advantage. They’ll have stable teams that know their systems, they’ll spend less time onboarding new vendors, they’ll move faster because trust removes friction. In a market where so many organizations outsource to access talent and improve performance, the quality of that partnership matters as much as the cost.
What Matters Here?
After working through the evidence, the CMS → revenue connection mostly comes down to a few channels:
– Page speed and Core Web Vitals shape bounce rate and viewbility and often influence SEO outcomes;
– Session depth is driven by recirculation and editorial workflows that your CMS either supports or blocks;
– Testing infrastructure enables continuous optimization of headlines, layouts, and ad placements;
– Scalability preserves revenue during high-demand moments;
– Ad tech flexibility lets you iterate on monetization without engineering bottlenecks.
None of this requires the most expensive platform on the market, but it requires architecture that’s built around performance and iteration (and a setup that doesn’t punish you for changing your mind).
The Classical Bottom Line
Your CMS is infrastructure, right? For publishers that infrastructure either supports modern ad optimization or works against it.
But we can’t leave you without the good news: these problems are solvable. Whether it’s targeted improvements or a planned migration, the path from underperforming architecture to a revenue-ready platform is known. The first step is seeing the CMS as part of your monetization engine. Because you know that it is.
Read our articles on other topics:
Privacy-First AdTech And What To Wait From It in 2026?
CMS Migration Challenges: What Goes Wrong And How to Avoid It